

RNN의 종류(입출력 개수에 따라)
- one to one : 이미지 캡쳐닝 cv +nlp 이미지에 대한 자막 다는 것. 이미지 -> 시퀀스 of words
- many to one : sentimental classification (sequence of words -> sentiment) 텍스트 리뷰 등 받아서 긍정 부정 출력
- many to many : machine translation (seq of words -> seq of words) 기계 번역
RNN이 잘 쓰이지 않은 이유 : 학습이 잘 안 됨, 문제: 기울기 소실&폭발 = Degradation
Vanilla RNN은 기울기 문제 때문에 사용화는 안 됐음. 이후 LSTM으로 상용화 가능성 발견함

tanh 함수
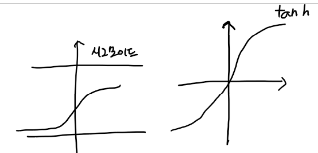
시그모이드 함수의 변형 중 하나입니다. 즉, 탄젠트도 일종의 시그모이드
시그모이드 함수는 다음과 같이 표현됩니다:
sigma(x) = \frac{1}{1 + e^{-x}}
반면에 tanh 함수는 하이퍼볼릭 탄젠트(hyperbolic tangent) 함수로 불리며 다음과 같이 정의됩니다:
tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}}
두 함수 모두 입력 값을 0에서 1 또는 -1에서 1 사이의 값으로 압축하여 출력하는 특징을 가지고 있습니다. 그러나 주요한 차이점은 tanh 함수가 원점 대칭이라는 점입니다.
즉, 입력 범위가 -∞에서 ∞로 확장되며 0을 중심으로 대칭적으로 출력됩니다.
이와 달리 시그모이드 함수는 0에서 1 사이로 압축되며 0과 1에 가까워질수록 미분값이 작아지는 문제가 있습니다.
tanh 함수는 입력의 범위가 넓을 때, 특히 활성화 함수로 사용될 때 훨씬 더 좋은 결과를 얻을 수 있는 경우가 많습니다. 그래서 tanh 함수는 신경망의 은닉층에서 자주 사용되곤 합니다.
순전파 : 예측값을 계산해 나가는 과정
역전파 : back-propagation 오차를 계산을 나가는 과정
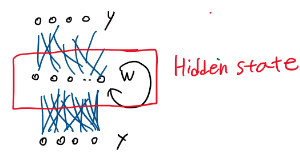
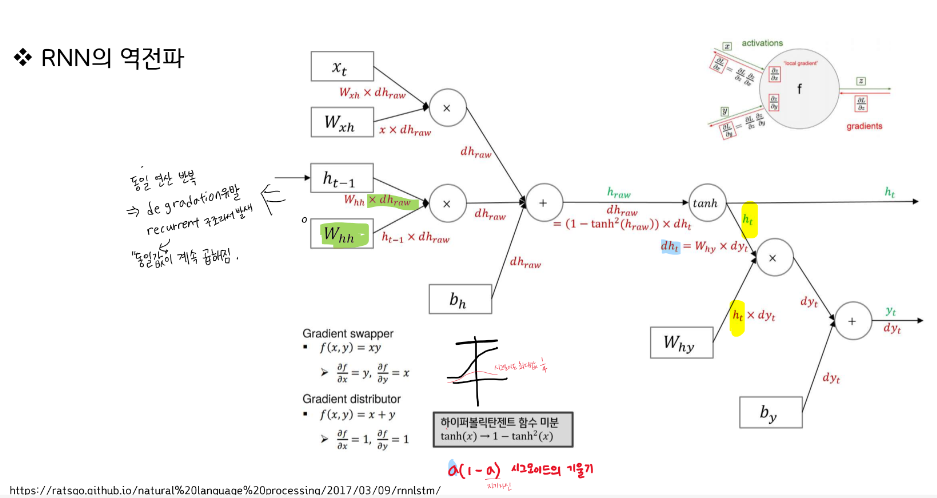
순환 구조 특성상 기울기 소실이 더 일어나기 쉽다.
Cost err가 있을 때 순환하면서 기울기가 소실/폭발 되며 전달이 안 됨
똑같은 구조 반복, 체인룰에 의해 똑같은 값이 나와서 곱해야 함
각 구간의 그래디언트가 동일하게 나오기 때문에 모두 곱해줘야 함.
하이퍼볼릭 탄젠트는 최대 기울기가 1까지 나옴
시그모이드는 최대값이 1/4
recurrent 구조 -> Degradation
LSTM
LSTM 아이디어를 통해 Degradation 문제 해결함. 단, 근본적인 해결은 아님.
그래디언트가 계속 바뀐다. 동일한 구조이지만 역전파할 때 연산 그래디언트가 다른 그래디언트로 나올 수 있도록 하는 연산 장치임

RNN 실습
아키텍쳐 그릴 땐 batch size 고려하지 않고 그림
but, model Sequential 그릴 땐 batch size 넣음, 자리 필요
실제 코드엔 batch size 넣어야 함.
batch size 넣지 않으면 None으로 나옴

시퀀스:
시퀀스(Sequence)란 일련의 데이터나 사건들이 순서대로 배열된 것을 말합니다. 시퀀스 데이터는 시간이나 순서에 따라 변화하는 정보를 포함하고 있습니다. 예를 들어, 문장은 단어들의 시퀀스이며, 시계열 데이터는 시간에 따라 기록된 값들의 시퀀스입니다.
리턴 시퀀스를 주면 타임스탬프 값만큼 리턴할 게 남음. 중간 계산된 값을 확인할 수 있음
주지 않으면 잘림. 최종값만 확인됨
return_sequences = True,
return_sequences = False 언급 안 하면 False

batch size : 문장의 개수. 즉, 그러한 문장이 몇 개 인가
time stamp : 문장의 길이, 문장의 토큰 수를 의미 (나는 밥을 먹는다....)
input_shape=(time stamp 문장의 토큰 수, 벡터의 크기 n = feature )

다층 Simple RNN
임의의 시계열 데이터
X, y 데이터 생성하기
다음으로, 해당 샘플 데이터를 1칸씩 이동하며 10개씩 데이터를 잘라, x값으로 사용하고, y값은 11번째 데이터로 사용하겠습니다.
예) x = 1번째 ~ 10번째 데이터 / y = 11번째

'AI, 머신러닝, 딥러닝, 데이터 분석' 카테고리의 다른 글
| AlexNet ImageNet Claasification with Deep Convolutional Neural Networks _ Geoffery E. Hinton (0) | 2023.08.31 |
|---|---|
| 딥러닝 LSTM(Long Short Term Memory) (0) | 2023.08.30 |
| [프로그래머스] 파이썬 최댓값 만들기 ver. 2 (0) | 2023.08.07 |
| [논문 요약] 추천 시스템 기법 연구동향 분석 - 콘텐츠 기반 접근 방식 (1) | 2023.08.04 |
| [추천 사이트] Paperwithcode AI 논문과 코드가 있는 사이트 (0) | 2023.08.01 |



